Web Crawler

Web Crawler
A GUI-based Python tool for crawling websites, managing proxies, respecting robots.txt rules, and exporting data in HTML, JSON, or CSV formats.
Web Crawler Repository
- Link: Web Crawler Repository
Features
- GUI Interface: A user-friendly graphical interface for configuring and controlling the crawler.
- Robots.txt Compliance: Automatically checks and respects website crawling rules defined in
robots.txt. - Proxy Management: Supports proxy rotation to avoid IP blocking during large-scale crawls.
- URL Filtering: Includes and excludes URLs based on customizable patterns and domain restrictions.
- Real-Time Statistics: Displays live metrics such as pages crawled, memory usage, queue size, and errors.
- Data Visualization: Provides dynamic graphs for crawl speed, memory usage, and URLs in the queue.
- Export Options: Export crawled data in HTML, JSON, or CSV formats for further analysis.
- Pause/Resume/Stop: Full control over the crawling process with pause, resume, and stop functionality.
- Concurrency: Configurable number of concurrent workers for efficient crawling.
How It Works
The Enhanced Web Crawler is a Python-based desktop application designed to extract structured data from websites while adhering to ethical crawling practices. Here’s how it works:
- Input Configuration:
- Enter the starting URL, maximum depth, and other settings like the number of concurrent workers and rate limits.
- Add include/exclude URL patterns to filter which pages should be crawled.
- Crawling Process:
- The tool checks
robots.txtcompliance before crawling any page. - It uses proxies (if configured) to rotate IPs and avoid being blocked.
- URLs are processed concurrently using a thread pool, ensuring efficient crawling.
- The tool checks
- Data Extraction:
- Extracts metadata such as page titles, links, and timestamps.
- Stores the crawled data in memory for real-time updates and visualization.
- Monitoring and Export:
- Real-time statistics and visualizations help monitor the crawling process.
- Once crawling is complete, export the results in HTML, JSON, or CSV formats for further analysis.
Code Structure
The project is organized into modular components for clarity and maintainability:
crawler/: Core functionality for crawling, proxy management, robots.txt parsing, and statistics tracking.proxy_manager.py: Manages proxy rotation.robots.py: Handles robots.txt compliance.stats.py: Tracks crawling statistics.url_filter.py: Filters URLs based on patterns and domains.
gui/: Implements the graphical user interface.dashboard.py: Displays real-time statistics and logs.visualization.py: Provides dynamic graphs for monitoring the crawl process.
webcrawler.py: Entry point of the application, initializes the GUI and starts the crawler.
Interface
The interface includes:
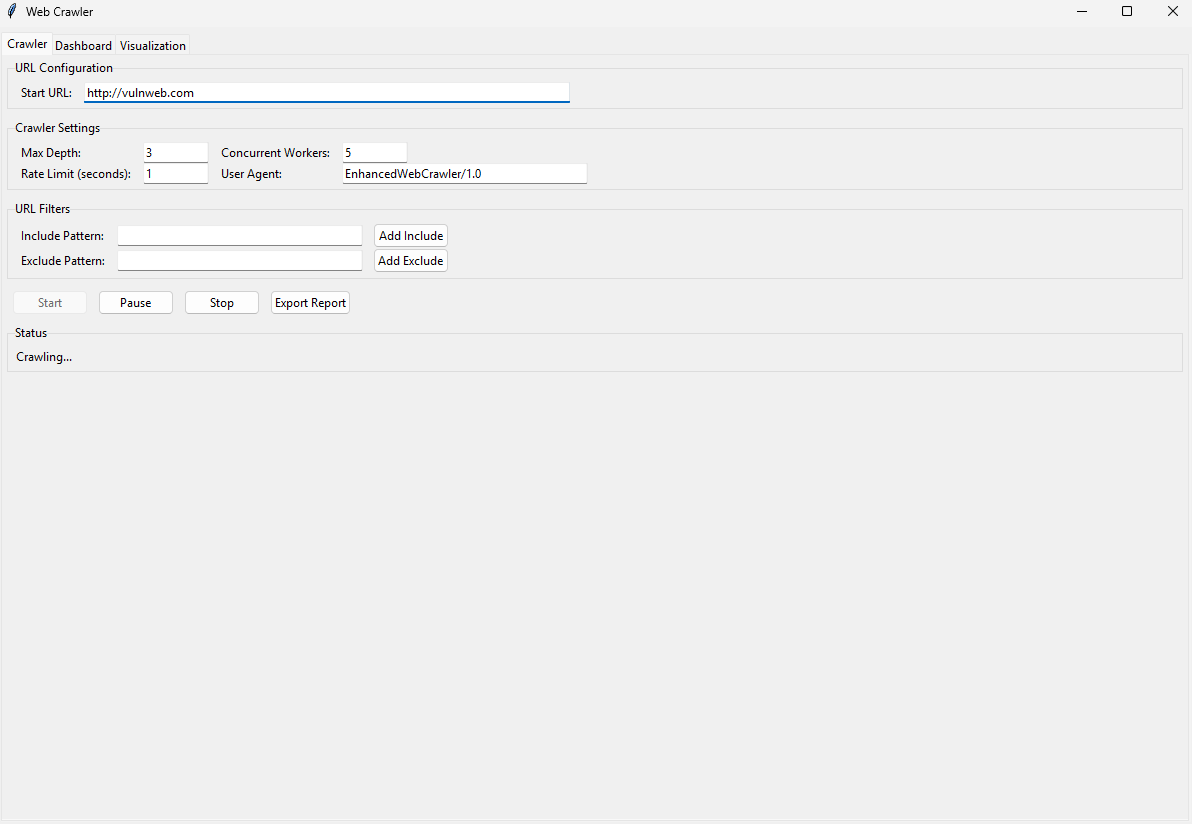
- Crawler Tab: Configure settings, start/pause/stop crawling, and view status.
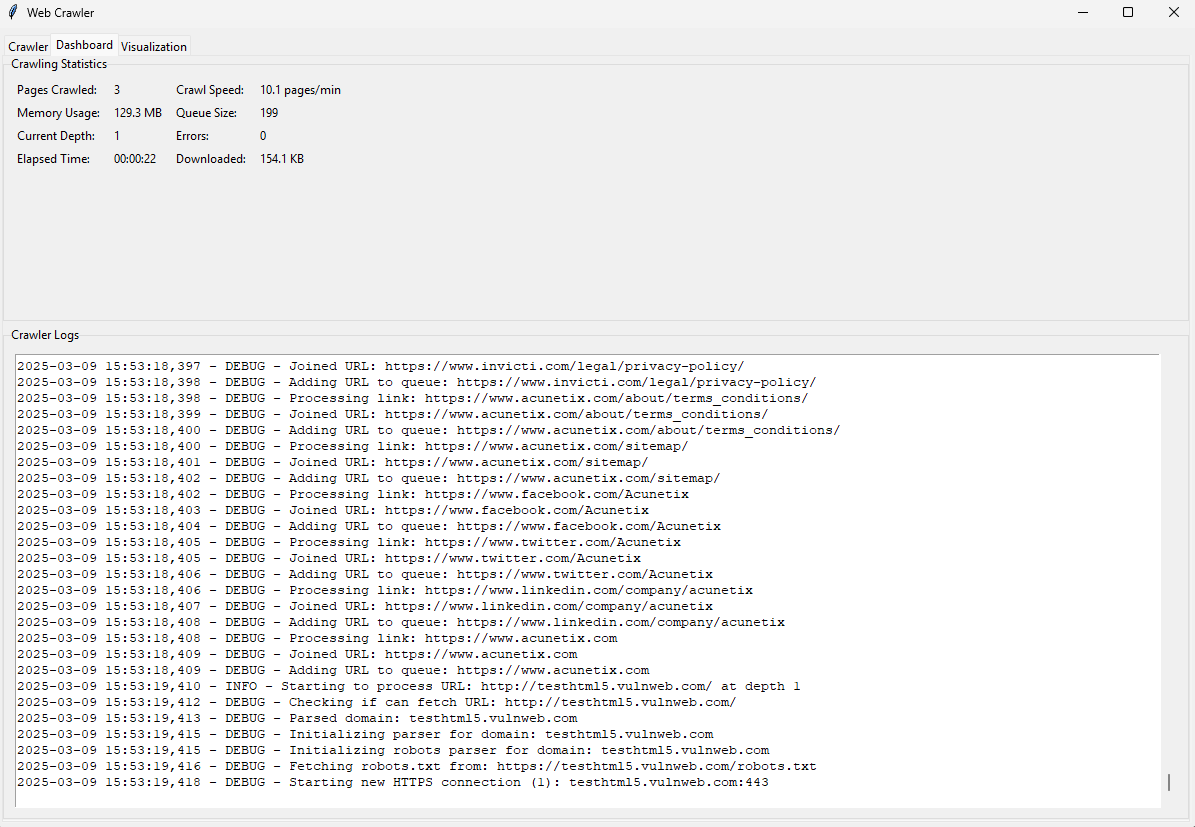
- Dashboard Tab: Monitor real-time statistics and logs.
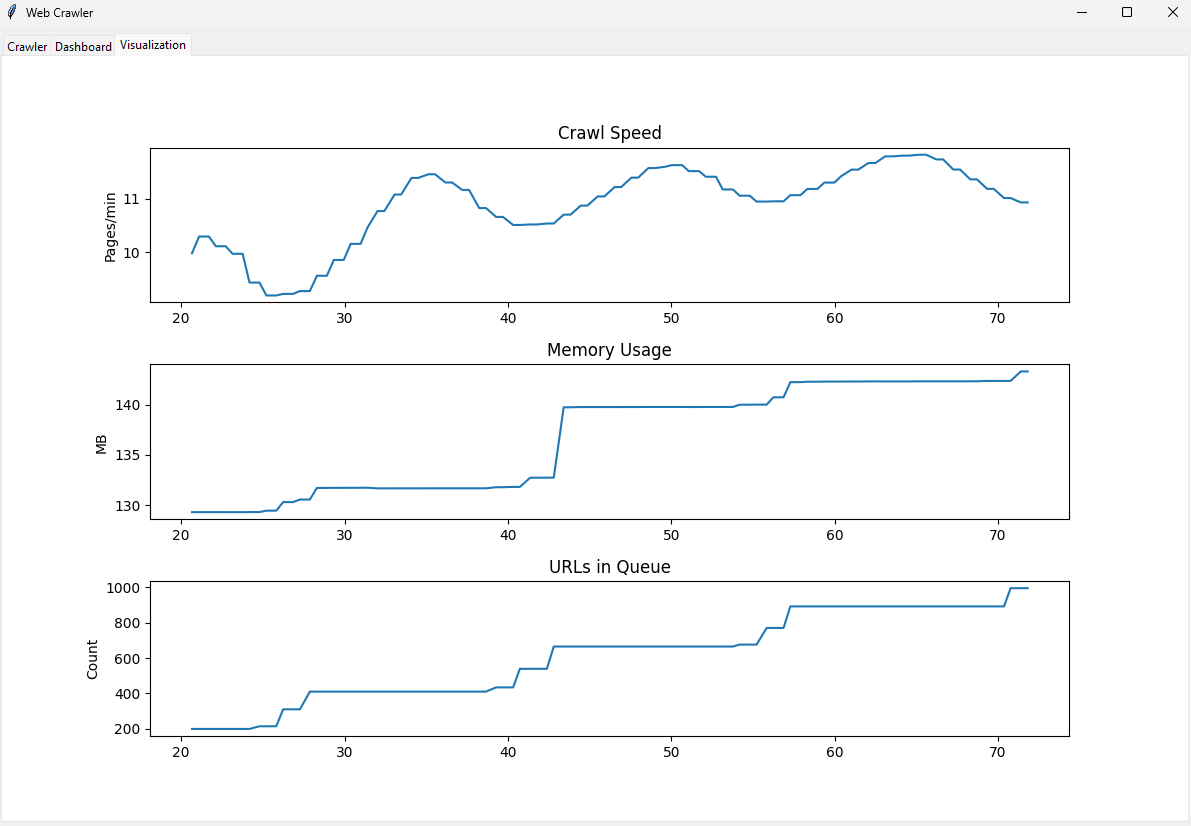
- Visualization Tab: View dynamic graphs for crawl speed, memory usage, and URLs in the queue.
Future Enhancements
- Advanced Export Options: Support additional export formats like XML or Excel.
- Improved Proxy Handling: Add support for authenticated proxies and automatic proxy fetching.
- Database Integration: Store crawled data directly in a database for large-scale projects.
- Enhanced Visualizations: Add more detailed graphs and analytics for crawled data.
- Error Recovery: Implement automatic retry mechanisms for failed requests.
Ethical Considerations
The Enhanced Web Crawler is designed with ethical considerations in mind:
- Respect for Robots.txt: The tool automatically checks and adheres to
robots.txtrules to ensure compliance with website policies. - Rate Limiting: Users can configure rate limits to avoid overloading servers with too many requests.
- Proxy Rotation: Helps distribute requests across multiple IPs, reducing the risk of overwhelming a single server.
- Transparency: Clear documentation ensures users understand how to use the tool responsibly.
Always ensure that you have permission to crawl a website and that your actions comply with applicable laws and terms of service.
This post is licensed under CC BY 4.0 by the author.